
背景
所在项目在做微信小程序的相关产品,目前项目还处于技术预研(踩坑)阶段。由于之前没有接触过骨架屏,所以十分心动,遂主动负责了这部分。本文记录总结了对于骨架屏实现的几种方案,供大家参考
⚙️预研方案一、 引入静态文件
引入静态文件应该是最容易想到的骨架屏解决方案。
引入静态文件这点很好理解,其实就是为每个需要在加载的时候显示骨架屏的页面都编写一个骨架屏文件,并在相应的页面中引入编写好的骨架屏页面。比如我有一个页面pages/牛牛/牛牛.wxml,那么我需要为这个页面编写一个单独的wxml文件,当页面处于加载状态时显示这个骨架屏页面pages/牛牛/牛牛.skeleton.wxml。
如果骨架屏页面较多,那么可以思考一下,对于页面中骨架屏展示的内容基本都是下图的形式,当然内容和结构可能会多种多样。
但是细细想来,骨架屏中的内容基本都是由几种特定的规则图形来展现,如:圆形、矩形、圆角矩形等。所以,我们可以像普通的组件化开发一样,将一些通用的骨架屏内容抽成更加可用的组件。
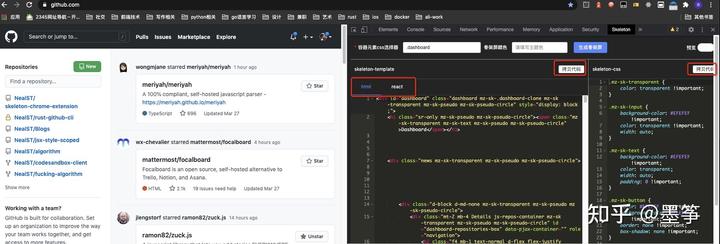
当然微信开发者工具也提供了生成骨架屏的功能:
当我们点击后,开发者工具会在dist中的当前页面目录下生成两个文件:page_name.skeleton.wxml和page_name.skeleton.wxss,剩下的方式就和我们引入静态文件的方式是一样的!下图为引入后的效果:
可以看出自动生成的骨架屏的效果还是不太能满足我们,最上面我们自定义的navigation-bar也变成了骨架屏,这显然不是我们想要的,当然我们可以手动修改自动生成的page_name.skeleton.wxss文件。说到底微信生成的骨架屏与我们自己实现的方式一样,可以看一下生成的牛牛.skeleton.wxml文件:
<view is="pages/牛牛/components/公告/公告">
<view
class="sk-transparent sk-text-28-5714-913 sk-text"
style="background-size: 62.2159% 2.1875rem;"
>
这是牛牛页面的公告组件
view>
view>
生成的文件中,将我们的页面wxml中的内容添加相应的class,并在page_name.skeleton.wxss加入相应样式。
同时,每个class都还有相应的编码:
.sk-text-28-5714-913 {
background-image: linear-gradient(transparent 28.5714%, #EEEEEE 0%, #EEEEEE 71.4286%, transparent 0%) !important;
background-size: 100% 2.1875rem;
position: relative !important;
}
这也就意味着,当我们再次使用生成骨架屏的功能之后,我们之前的修改也会随之删掉!!!这种方式也很难用版本控制来管理生成的骨架屏文件。开发过小程序的小伙伴应该知道,小程序会有包体积的限制,从我上面描述的可以看出微信生成骨架屏的方式生成的文件会有很多重复且冗余的代码,这无疑也增加了小程序包的体积。
同时,当设计的界面发生变化时,对于引入静态文件的方式也是十分不友好的,设计界面的改变导致相应的骨架屏实现也要随之修改!
二、动态计算
动态计算是指当用户进入界面的时候,我们使用微信提供的一些API的去获取当前页面一些指定区块的信息(如坐标、尺寸等),然后在相应的坐标处绘制与指定区块相同大小的灰色区域来实现骨架屏效果。
实现起来十分简单,首先在我们需要显示骨架屏的页面引入骨架屏组件,同时为需要展示位骨架屏的组件或者节点添加指定class,此处特定class为skeleton-rect,含义为“矩形骨架屏”:
<skeleton wx:if="{{loading}}">skeleton>
<view wx:else>
<公告 class="skeleton-rect">公告>
<内容 class="skeleton-rect">内容>
view>
下面微信小程序组件传值,我们开始着手实现骨架屏组件:
// skeleton.ts
// 此处使用的@vue-mini/wechat小程序框架
// 此框架为项目组同事开发,感兴趣的小伙伴可以去GitHub查看(疯狂打call)
defineComponent({
setup() {
function getSkeletonStyles(selector: string, ref: Ref) {
wx.createSelectorQuery()
.selectAll(selector)
.boundingClientRect()
.exec(results => {
ref.value = results[0].map((rect: WechatMiniprogram.Rect) => {
const { height, width, left, top } = rect
return `position: absolute;
height: ${height}px;
width: ${width}px;
left: ${left}px;
top: ${top}px;
background-color: lightgray;
`;
});
});
}
const skeletonRectsStyles = ref<string[]>([]);
getSkeletonStyles('.skeleton-rect', skeletonRectsStyles);
return {
skeletonRectsStyles,
};
},
});
<view class='skeleton-contianer'>
<view
wx:for="{{skeletonRectsStyles}}"
wx:key="index"
style="{{item}}"
>
view>
view>
wxml文件就不做过多介绍,在ts文件中,当组件setup(生命周期参照Vue3 Composition API)时我们使用wx.createSelectorQuery获取到所有具有skeleton-rect class 的节点,然后通过boundingClientRect获取到每个节点的绝对位置以及尺寸,然后组合成样式字符串储存进skeletonRectsStyles中供我们在wxml中使用。效果如图:
当然可以看出一些问题,在公告以及内容组件中我们会使用到margin以及padding等方式来调整样式,我们获取到的尺寸是包含了margin等信息的,所以动态计算生成的骨架屏显示出来会有些问题,如比加载完毕后显示的效果更加大一些,或者甚至于有些区块连接在一起。
三、组件内部管理
组件内部管理是指将骨架屏封装至各个组件中,由组件自己管理。当页面处于加载状态时,给需要显示骨架屏的组件传入特定值来标识当前组件需要展示骨架屏状态,然后在组件内部添加相应的class,从而通过样式文件再给特定的class添加骨架屏效果。
我们以antd的Card组件为例:
当页面还处于加载状态时,antd将loading设置为true,下面来看一下Card组件的实现:
const Card: CardInterface = props =>
// ...
const classString = classNames(prefixCls, className, {
[`${prefixCls}-loading`]: loading,
// ...
});
//...
return (
{/* 其它逻辑 */}
</div>
);
}
源码请见:#L187
&-loading {
overflow: hidden;
}
&-loading &-body {
user-select: none;
}
&-loading-content {
p {
margin: 0;
}
}
&-loading-block {
height: 14px;
margin: 4px 0;
background: linear-gradient(90deg, @gradient-min, @gradient-max, @gradient-min);
background-size: 600% 600%;
border-radius: @card-radius;
animation: card-loading 1.4s ease infinite;
}
源码请见:#L257
对于一些不太复杂的项目这种方案无疑会增加很多工作量,与此同时组件还需要接收传入的特定标识来判断组件是否需要展示骨架屏,这种方式对组件的入侵性也比较严重,对于组件而言也比较繁重。
四、 图像识别
在Code Review的时候,同事突发奇想说“如果能用图像识别来识别区域,然后生成骨架屏那就好了”,于是第二天我就开始研究这种方式的可行性,你别说还真行!目前图像识别这种方式使用的是NodeJS版的OpenCV来实现。我们先以腾讯会议小程序的界面为例:
然后我们使用OpenCV来绘制并相应区域效果:
实现的效果不好,但是起码说明这种方式是行得通的!如要绘制的更加精细准确,那么接下来的工作就是调参了。先来看一下实现:
const cv = require('opencv');
const lowThresh = 0;
const highThresh = 255;
const nIters = 10; // 膨胀值
const WHITE = [255, 255, 255]; // 定义白色
cv.readImage('./images/TencentMeeting.jpg', function(err, im) {
if (err) throw err;
const width = im.width(); // 获取图片宽度
const height = im.height(); // 获取图片高度
if (width < 1 || height < 1) throw new Error('Illegal image size!');
im.convertGrayscale();
im_canny = im.copy();
/*
* 计算边界,如果低于lowThresh阈值就抛弃,如果高于highThresh则视为边界,
* 介于二者中间,就要看这个点是否与边界相连,如果相连则视为边界点,否则抛弃
*/
im_canny.canny(lowThresh, highThresh);
im_canny.dilate(nIters);
// 查找轮廓
const contours = im_canny.findContours();
// 绘制轮廓并输出保存为图片
const all = new cv.Matrix(height, width);
all.drawAllContours(contours, WHITE, -1);
all.save('./images/TencentMeeting.skeleton.jpg');
});
代码注释写的还是比较详细的,就不在此赘述,如有疑问可查阅OpenCV相关文档。
这种方式虽然很方便,但在使用图像识别的方式时,前提是我们有图像微信小程序组件传值,假如我们使用原型图作为图像识别的图像来源,那么绘制出的图像应该是与原型图比例一致的图像。假如原型图是基于iPhone6/7/8设计的,那么当我们绘制出的图像在iPhoneX(及其他分辨率的手机)上显示时可能会发生形变。
✌️结束语
上述四种方式各有利弊,具体使用哪一种还是要看项目倾向以及团队精力来合理选择。引入静态文件的不见得是最繁杂的,当然图像识别也不一定是最安逸的。并且上述方案也不仅限于小程序项目,其它形式的项目也可参考。
本次分享到此结束,本文没有彩蛋,感谢阅读!
小彩蛋我们的故事怎么会戛然而止!如果你要问我:“你们项目到底使用的哪一种?”
我们打算交给UI vendor来负责,不愧是我们,哈哈哈哈哈哈哈哈哈!!!
版权声明
本文仅代表作者观点。
本文系作者授权发表,未经许可,不得转载。

发表评论