首页
留言本
丛德网络
搜索
获取
丛德网络
0
简短的爬虫程序,14行Python代码轻松实现爬取网站视频
2023.10.22 |
admin
| 105次围观
### 回答1:下面我以爬取豆瓣电影Top250为例,简要介绍一下Python编写爬虫的过程。1. 确定网站URL首先需要确定要爬取的网站的URL,这里我们选择豆瓣电影Top250的页面:2. 分析网页结构在爬取网页数据前,需要先分析网页的结构,确定需要获取的数据的位置和方式。可以使用浏览器的开发者工具来查看网页的HTML结构。在这个例子中,我们要获取电影名称、评分、导演、主演、上映年份和电影海报等信息。3. 发送HTTP请求使用Python的requests库发送HTTP请...
丛德网络
0
requests或selenium获取网页内容不全问题(非异步加载)
2023.10.18 |
admin
| 186次围观
最近用python做脚本的时候,发现了一个问题,就是获取的网页并不全。可能原因之一是页面内容过大,无法加载全部到内存中 下面的解决方法只针对静态加载页面(有的网页是动态加载数据,需要查看对应的js请求或者用selenium来获取就好)。 解决方法为放入文件里,再读取即可 使用selenium,代码如下 browser = webdriver.Chrome(service=webdriver_service, options=option) browser.get(url) b...
丛德网络
0
3步教你用网络爬虫爬取股票数据,内附完整程序代码
2023.08.11 |
admin
| 126次围观
人工智能时代,大数据的获取至关重要,利用网络爬虫获取数据是当前最有效的手段。爬虫本质上就是代替人工操作访问网站,自动找到目标数据,并获取目标数据的过程。今天不谈任何协议结构,只通过结合爬取股票数据的代码介绍最基本的爬虫实现,力求让略有python基础的爱好者有一个直观印象。 任务:爬取东方财富网上以6开头(比如浦发银行600000)的股票数据(最高价、换手率、成交量和成交额)。首先在东方财富网()获取全部股票代码列表网页图片源代码怎么看,然后访问百度股市通(+股票代码)获取具...
丛德网络
0
java对接大华SDK摄像头监控
2023.08.08 |
admin
| 211次围观
### 回答1:Java大华视频流对接是指使用Java编程语言对接和调用大华视频流服务。在对接过程中,可以使用Java提供的网络编程和多线程技术,通过访问大华视频流服务的API接口,获取视频流数据,并进行相应的处理和展示。要实现Java大华视频流对接,可以按照以下步骤进行:1. 导入相关的Java库和依赖项,以便能够使用Java提供的网络和多线程功能。2. 创建与大华视频流服务的连接。可以通过建立网络连接,或使用提供的SDK等方式进行连接。3. 进行用户认证。根据大华视频流服...
丛德网络
0
微信小程序中怎么生成一个分享海报
2023.07.25 |
admin
| 138次围观
这篇文章给大家介绍微信小程序中怎么生成一个分享海报,内容非常详细微信小程序生成海报,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。 let shareInfo = { headerImg: 'tempfilepath', bgImg: '本地路径的图片', qrcode: 'tempfilepath' } wx.navigateTo({ url: '/pages/createPoster/main?shar...
丛德网络
0
最新微信小程序反编译工具,完美解决分包问题
2023.07.23 |
admin
| 154次围观
看了很多反编译、找回微信小程序源码很多教程,各种问题导致都没法正常使用。微信版本升级后,会遇到各种报错, 以及无法获取到wxss分包无法反编译的问题。于是寻找资料,也买过别人的破解工具,最终解决文件缺失和分包问题,而且无意中发现还能获取小游戏的源码,于是和大家分享下。 一、在这里获取小程序的.wxapkg包我就不多介绍了 方法一:电脑安装已经root的模拟器 安装微信和re文件浏览器 运行小程序后在re文件浏览器的/data/data/com.tencent.mm/Micro...
丛德网络
0
获取服务器信息目录失败是怎么回事,获取服务器列表失败
2023.07.23 |
admin
| 152次围观
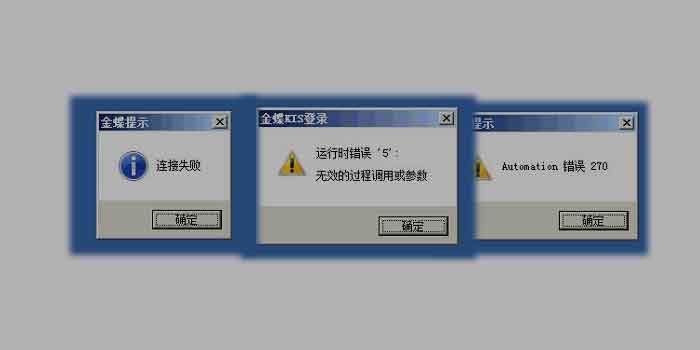
获取服务器列表失败...这种是什么错误,是怎么回事呢?我相信很多成人都遇到过这种错误,无论你是玩家还是开的GM,既然有问题,那么比如就会有解决的方法,今天我们就说说获取服务器列表失败...(是怎么回事)附解决方法这篇文章了,传奇爱好者站长就为大家系统和全面的说说这个错误是怎么诞生的,以及如何解决? 在解决错误的第一步就是要知道错误是什么样子的,站长截图一张,这样可以让大家更加确切的知道错误是什么样子的。 获取服务器列表失败...这个错误我们已经看到了。接下来的时候就是说说如何...
丛德网络
0
微信小程序获取权限(相机、麦克风等权限)
2023.07.20 |
admin
| 123次围观
开发小程序不可避免的需要获取一些设备权限,例如相机、麦克风、保存到相册等权限,这里介绍一下 流程 获取一个权限,我们先通过wx.getSetting查看当前这个权限的情况,可能会有3种情况, 以麦克风权限scope.record为例: 打开小程序设置界面 想要打开小程序的这个设置页面无法获取摄像头数据 请检查是否已经打开摄像头权限,有2种方法: 这两种方法都需要用户主动点击触发,我们可以写一个button或者modal组件,放在页面中,或者写一个包含按钮的获取权限的页面。 这...
丛德网络
0
两个步骤让你获取任何微信小程序源码!
2023.07.17 |
admin
| 133次围观
最近在学习微信小程序开发,半个月学习下来,很想实战一下踩踩坑,于是就仿写了一个滴滴他们家的青桔单车小程序的前端实现,过程一言难尽,差不多两周时间过去了,发现小程序的坑远比想象的要多的多!!在实际练手中,完全是黑盒的,看到人家上线的小程序的效果,纯靠推测,部分效果在绞尽脑汁后能做出大致的实现,但是有些细节,费劲全力都没能做出来。很想一窥源码,查看究竟,看看大厂的前端大神们是如何规避了小程序的各种奇葩的坑。 于是就想到获取到小程序地源文件,然后再对其进行反编译还原为源代码,来作为...
丛德网络
0
梦幻西游称谓怎么获取 各类型称谓获取方法
2023.07.14 |
admin
| 134次围观
梦幻西游手游中,有着众多称谓,那么这些称谓该怎么获取,有哪些方法呢,下面一起来看看吧。 梦幻西游系列软件最新版本下载 226.00MB 梦幻西游互通版 立即下载 710.00MB 梦幻西游 立即下载 一,比武称谓 要说比武首当其冲的应该是每周日的比武大会,除了能够在比武大会中大展拳脚,积分第一的玩家还能获得英雄会状元的称谓,排名在2、3、4、5的玩家也能获得相应的称谓。 其次是每周六的决战华山,也是展现玩家实力的PK活动梦幻西游服务器列表获取失败梦幻西游服务器列表获取失败,在...
丛德网络
0
微信小程序知识点总结-1
2023.07.07 |
admin
| 180次围观
˂button bindtap="navigateBack"˃返回上一页 navigateBack: function () { wx.navigateBack({ delta: 1, // 返回的页面数,1表示返回上一级页面 success: function(res) { console.log("返回成功"); }, fail: function(res) { console.log("返回失败"...
丛德网络
0
怎么用js获取年月日
2023.07.01 |
admin
| 128次围观
在JavaScript中有Date()时间库,利用Date()获取时间对象js生成10位时间戳,利用时间对象可以获取完整的年、月、日、时、分、秒,还可以对所获时间进行格式化。 获取年、月、日和将时间戳转换成日期格式 // 简单的一句代码 var date = new Date(时间戳); //获取一个时间对象 /** 1. 下面是获取时间日期的方法,需要什么样的格式自己拼接起来就好了 2. 更多好用的方法可以在这查到 -˃ http://www.w3school.com....
丛德网络
0
打不开网页的原因以及解决办法,需要技巧
2023.06.28 |
admin
| 134次围观
步骤/方法 01 由DNS错误导致的IE打不开网页,通常是由于DNS服务器自身问题,或者用户设定的dns服务器地址有误。使用宽带上网的用户,dns是自动获取的,对于此类能上 qq打不开网页的现象,可以使用ipconfig /flushdns命令来重新获取;或者将dns服务器地址设置为8.8.8.8(这是Google提供的免费域名解析服务器地址)。局域网内的用户,如果打不开网页,且看到DNS错误的提示,大多是网关设置出现问题,需要网管解决。 02 ie浏览器组件被病毒修改导致的...
丛德网络
0
chatgpt赋能python:Python爬取电影简介
2023.06.23 |
admin
| 163次围观
Python 爬取电影简介 随着互联网技术的逐步普及,越来越多的人已经建立了自己的个人网站或博客,而如何让自己的网站获得更好的 SEO 排名,吸引更多的流量就成了一个非常重要的问题。其中,内容的质量和数量是关键的,而提供原创、有价值的文本内容已经成为了每个网站负责人的职责。而爬取数据是获取高质量内容的一个重要途径之一。本篇文章将围绕着 Python 爬取电影这一话题,简单介绍如何使用 Python 爬取电影网站的数据,并且讨论一些在爬取过程中需要注意的事项。 为什么要使用 P...
丛德网络
0
高效抓取页面JS代码,让复制粘贴远离你
2023.06.22 |
admin
| 132次围观
在网站开发过程中,JS代码是不可或缺的一部分。但是,有时候我们需要获取网站上的JS代码,这时候手动复制粘贴显然不是一个好的选择。这时候,页面js代码抓取工具就应运而生了。 一、什么是页面js代码抓取工具? 页面js代码抓取工具是一种可以自动化抓取网页上JS代码的工具。它可以很方便地获取网站上的JS代码,并将其保存到本地文件中。 二、为什么需要使用页面js代码抓取工具? 1.方便快捷:使用页面js代码抓取工具可以让你轻松快速地获取网站上的JS代码,省去了手动复制粘贴的繁琐过程。...
丛德网络
0
教你轻松解决Win7系统经常获取不到IP地址问题
2023.06.19 |
admin
| 147次围观
教你轻松解决Win7系统经常获取不到IP地址问题 近段时间,有朋友遇到笔记本Win7系统经常获取不到IP地址,右下角显示黄色感叹号图标,而其他同事的电脑上网一切正常,不管是XP系统,还是win7系统或是Vista系统。下面学习啦小编同大家分享一下解决方法,希望以后遇到此问题的朋友通过此解决,希望对您有所帮助! 教你轻松解决Win7系统经常获取不到IP地址问题 1、线路连接是否正确及线缆是否损坏? 采用的是有线路由器连接方式,所以第1步检查的就是线路连接是否正确,发现物理线路没...
丛德网络
0
Js获取指定时区的时间
2023.06.01 |
admin
| 153次围观
需求:如果你现在美国,通过new Date()获取的是当地时间。而你想知道知道此时北京的时间是多少?反过来思考,如果你现在在国内,如何获取指定时区的时间呢?设置系统时间为美国时间,通过new Date()获取当地时间: 如何获取北京时间并展示在页面? // 获取指定指定时区时间(北京时区为8,纽约时区为-5。东时区为正数,西市区为负数) function getTimeByZone(timezone = 8, date) {...
丛德网络
0
微信小程序wxml如何判断字符串中汉语某字符_如何获取别人微信小程序的源文件?
2023.05.30 |
admin
| 137次围观
如何获取别人微信小程序的源文件? ·简单聊一下 xxxxx.wxapkg 小程序的源文件存放在哪?(当然是在微信的服务器上) ·但是在微信服务器上微信小程序反编译神器,用户想要获取到,肯定是十分困难的,有没有别的办法呢? 简单思考一下我们使用小程序的场景就会明白,当我们点开一个微信小程序的时候,其实是微信已经将它的从服务器上下载到了手机,然后再来运行的。所以,虽然我们没能力从服务器上获取到,但是我们应该可以从手机本地找到到已经下载过的小程序源文件 ·那么如何才能在手机里找到小...
丛德网络
0
Js New Date()实例测试
2023.05.23 |
admin
| 229次围观
JS获取当前时间戳的方法-JavaScript 获取当前时间戳 JavaScript 获取当前时间戳: 第一种方法: var timestamp =Date.parse(new Date()); 结果:1280977330000 第二种方法: var timestamp =(new Date()).valueOf(); 结果:1280977330748 第三种方法: var timestamp=new Date().getTime(); 结果:1280977330748 第一...
丛德网络
0
Win8系统怎么获取开发者许可证?Win8系统获取开发者许可证的详细步骤
2023.05.12 |
admin
| 218次围观
win8系统推出了开发者许可证,不仅能增加Win8系统的商店应用数量,还能无限制免费获取商店应用离线安装包,但是要怎么获取开发者许可证呢?下面和小编一起来看看Win8系统怎么获取开发者许可证吧。 1、最先根据win8“检索”非常按键检索“WindowsPowershell”; 2、鼠标右键挑选“以管理人员真实身份运作”,开启“管理人员:WindowsPowershell”对话框; 3、随后键入“Show-WindowsDeveloperLicenseRegistration”...
丛德网络
0
PHP抓取指定标签:实战教程分享
2023.05.07 |
admin
| 233次围观
PHP作为一种强大的后端编程语言,可以很好地完成网页数据的抓取和分析。但是,如果要抓取网页中的指定标签,该如何实现呢?下面就来分享一下具体的实战教程。 一、分析目标网页结构 在开始编写代码之前,需要先分析目标网页的结构。通过开发者工具或者查看源代码去掉网页中分享到代码,我们可以定位到需要抓取的标签所在的位置,并获取到该标签的CSS选择器或XPath路径。 二、使用curl函数获取网页内容 在PHP中去掉网页中分享到代码,可以使用curl函数来获取指定URL的网页内容。通过设置...
丛德网络
0
电脑连不上无线网络总提示“正在获取网络地址” 如何才能重新获取Ip地址
2023.04.30 |
admin
| 364次围观
最近一位用户说电脑连接网络总显示“正在获取网络地址”,最终无法自动获取IP地址,尝试用手机、电脑、笔记本连接WiFi都显示正在获取网络。这个问题小编也遇到过,其实只要重启了一下路由器填写了密码解决了,所以下文告诉大家一下具体修复方法。 解决方法: 1、如当前电脑上网正常,首先同时按下Windows键和R键,输入cmd 点击确定,然后输入“netsh winsock reset”按下Enter键,等待显示操作成功以后关闭窗口,然后将无线网卡驱动程序重新安装以后使用观察。 (资料...
1
随机文章
10个让老司机悄悄成长的黑科技网站
当 ChatGPT 比你更会写代码,程序员还能干什么?
ChatGPT引发的人工智能创作著作权问题思考
为什么打不开网页(为什么浏览器打不开网页)
【IMX6ULL驱动开发学习】01.安装交叉编译环境【附下载地址】
电脑中文输入法不见了,按照这个方法进行设置,就可以恢复
CHs许可,许可证,盗版解决,license,资产,软件,管理
手机电脑互传文件,不是只有QQ、微信!
今日更新如何查看本机ip地址(如何查询电脑ip地址)
最近发表
微机控制与接口技术形成性考核册答案
手机百度浏览器如何翻译网页?
如何重置小米摄像头(如何重置小米摄像头云台版)
怎样将英文网页翻译成中文?
路由器ip地址怎么看
网站的标题、关键词可以修改吗?看看这些细节
路由器静态ip怎么改成动态ip
缘小白摄像头安app,小白摄像头安装
新手必看! 快速知道自己路由的IP地址
网站关键字可以修改吗
网站分类
丛德网络
文章归档
2023年12月 (83)
2023年11月 (146)
2023年10月 (156)
2023年9月 (46)
2023年8月 (1592)
2023年7月 (3715)
2023年6月 (2773)
2023年5月 (3670)
2023年4月 (2699)